My Favorite Mind Blowing ML/AI Breakthroughs
Posted on 2019-02-10 in machine learning
·7 min read
Compared to other fields, machine learning / artificial intelligence seems to have a much higher frequency of super-interesting developments these days. Things that make you say “wow” or even “what a time to be alive!” (as the creator of Two Minute Papers always says)
Disclaimer: I’m not using any rigorous definition of “mind-blowing” or “breakthrough”; it’s a casual list.. and I might use less rigorous terminology to make this post more accessible
Amazingly accurate estimates from seemingly unusable information
Through-wall human pose estimation
Website/video by MIT researchers, 2018

We can accurately estimate how a human on the other side of a wall is standing/sitting/walking just from perturbations in Wifi signals caused by that human.
Gauging materials’ physical properties from video
Article/video by MIT researchers, 2015
The researchers first demonstrated in 2014 that they can e.g. reproduce human speech from video (with no audio) of a potato chip bag based on the vibrations. This part was done without machine learning. In 2015, they used machine learning to show that you can estimate the stiffness, elasticity, weight per unit area, etc. of materials just from a video (in some cases just the vibrations caused by the ordinary circulation of air was sufficient).
Estimating keystrokes from a smartphone next to the keyboard
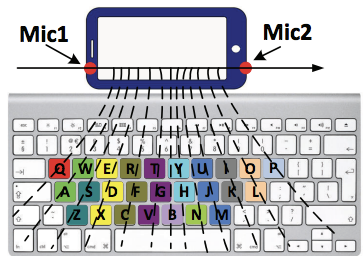
Researchers showed that with the audio recorded by a single, off-the-shelf smartphone placed next to a keyboard, one can estimate with 94% accuracy the individual keystrokes. Unlike previous approaches that used supervised deep learning with many microphones placed around the keyboard, this paper actually uses a relatively simple machine learning technique (K-means clustering) and unsupervised learning.
Generative models
Realistic face generation, style-mixing, and interpolation
Paper/video by NVIDIA researchers, 2018

The researchers combined a new architecture with tons of GPUs to create extremely photo-realistic artificial faces that are interpolations between other faces or applications of the “style” of one face to another face. The work builds upon past work on Generative Adversarial Networks (GANs). GANs were invented in 2014 and have seen an explosion in research since then. The most basic concept of GANs is two neural networks dueling against each other (e.g. one that classifies images as “real” or “fake” and a second neural network that generates images in a way that attempts to “trick” the first neural network into wrongly classifying fake images as real…hence the second neural network is an “adversary” to the first).
In general, there is a lot of awesome research about adversarial machine learning, which has been around for more than a decade. There are many creepy implications for cybersecurity etc. But I digress.
Teaching machines to draw
Blog post by Google Brain, 2017
 Interpolation between 2 drawings
Interpolation between 2 drawings
My acquaintance David Ha at Google Brain used a generative recurrent neural network (RNN) to make drawings that are vector-based graphics (I think of this as Adobe Illustrator except automated).
Transferring great dance moves to poor dancers
Website/video from UC Berkeley researchers, 2018
Think “Auto-Tune for dancing.” Using pose estimation and generative adversarial training, the researchers were able to make a fake video of any real person (the “target” person) dancing with great dance skills. The required input was only:
- a short video of someone with great dance skills dancing
- a few minutes of video of the target person dancing (typically poorly since most people suck at dancing)
I also saw Jensen Huang, the CEO of NVIDIA, show a video (made with this technique) of himself dancing like Michael Jackson. I’m glad I attended the GPU Tech Conference, haha.
Reinforcement learning
World models — AI learning inside its own dream

Humans do not actually know or think about all the details of the world we live in. We behave based on the abstraction of the world that is in our heads. For example, if I ride on a bike, I don’t think of the gears/nuts/bolts of the bike; I just have a rough sense of where the wheels, seat, and handle are and how to interact with them. Why not use a similar approach for AI?
This “world models” approach (again, created by David Ha et al) allows the “agent” (e.g. an AI that controls a car in a racing game) to create a generative model of the world/environment around it which is a simplification/abstraction of the actual environment. So, you can think of the world model as a dream that lives in the head of the AI. Then the AI can train via reinforcement learning in this “dream” to achieve better performance. So this approach is actually combining generative ML with reinforcement learning. By doing this, the researchers were able to achieve state-of-the-art performance on certain video game-playing tasks.
[Update 2019/2/15] Building upon the above “world models” approach, Google just revealed PlaNet: Deep Planning Network for Reinforcement Learning, which achieved 5000% better data efficiency than previous approaches.
AlphaStar — Starcraft II AI that beats the top pro players
Blog post, e-sports-ish video by DeepMind (Google), 2019
We’ve come a long way from the historic Go matches between Lee Sedol and DeepMind’s AlphaGo that rocked the world, which was a mere 3 years ago in 2016 (check out the NetFlix documentary, which made some people cry). Then, it was even more amazing that AlphaZero in 2017 became better than AlphaGo at Go (and better than any other algorithm at chess, shogi AKA Japanese chess, etc.) despite not using any training data from human matches. But AlphaStar in 2019 is even more amazing.
Being a StarCraft fan myself since 1998, I can appreciate how the “…need to balance short and long-term goals and adapt to unexpected situations… poses a huge challenge.” It’s truly a difficult and complex game which requires understanding at multiple levels to play well. Research on Starcraft-playing algorithms have been ongoing since 2009.
AlphaStar essentially used a combination of supervised learning (from human matches) and reinforcement learning (playing against itself) to achieve its results.
Humans training robots
Teaching tasks to machines with a single human demonstration
Article/video by NVIDIA researchers, 2018
I can think of 3 typical approaches to teaching robots to do something, but all take a lot of time/labor:
- Manually program the robot’s joint rotations etc. for each situation
- Let the robot try the task many, many times (reinforcement learning)
- Demonstrate a task to the robot many, many times
Typically, one major criticism of deep learning is that it’s very costly to produce the millions of examples (data) that make the computer perform well. But increasingly, there are ways to not rely on such costly data.
The researchers figured out a way for a robot arm to successfully perform a task (such as “pick up the blocks and stack them so that they are in the order: red block, blue block, orange block”) based on a single video of a single human demonstration (a physical real human hand moving the blocks), even if the video was shot from a different angle. The algorithm actually generates a human-readable description of the task it plans to do, which is great for troubleshooting. The algorithm relies on object detection with pose estimation, synthetic training data generation, and simulation-to-reality transfer.
Unsupervised machine translation
Blog post by Facebook AI Research, 2018
Typically, you would need a huge training dataset of translated documents (e.g. professional translations of United Nations proceedings) to do machine translation well (i.e. supervised learning). Of course, many topics and language pairs don’t have high-quality, plentiful training data. In this paper, researchers showed that it’s possible to use unsupervised learning (i.e. using no translation data and just using unrelated corpuses of text in each language), it’s possible to reach the translation quality of state-of-the-art supervised learning approaches. Wow.
The basic idea is that, in any language, certain words/concepts will tend to appear in close proximity (e.g. “furry” and “cat”). They describe this as “embeddings of words in different languages share similar neighborhood structure.” I mean, OK, I get the idea, but it’s still mind-blowing that using this approach they can reach such high translation quality without training on translation datasets.
Closing
I hope this post made you more excited about developments in ML/AI, if you weren’t already. Maybe I’ll write another similar post in a year from now. Please feel free to leave any thoughts/comments here or e-mail me at jerrychi123 [at] gmail.com.
What a time to be alive! =D